ThingsBoard 集成 Keycloak 自定义 OAuth2 认证服务器
目录
关注我们
关注 ThingsBoard 微信公众号
手动增加微信公众号:thingsboard_cn

访问 ThingsBoard 中文社区网站
访问网址:http://www.thingsboard.club

ThingsBoard 官方已经发布一些 OAuth2 支持的例子,https://thingsboard.io/docs/user-guide/oauth-2-support/,有 Google,Auth0,其他比如 GitHub 也比较简单。这里介绍的是 Keycloak 的配置。
如果你有 ThingsBoard 服务需求或二次开发需求,请与我们联系: 18616669123
1、前提条件
1.1、ThingsBoard Oauth2 支持
首先确保你的 ThingsBoard 服务器版本支持 OAuth2,比如 V3.3.*,以 sysadmin 登录即可。
1.2、Keycloak 服务器
安装
过程比较简单,可根据自身需求选择安装方式;测试的时候可以用 docker ,方便快捷。
阅读手册
找到你能读懂的文档,简单熟悉配置方法。
2、配置
2.1、Keycloak 配置
新建 realm

复制 secret

增加 user
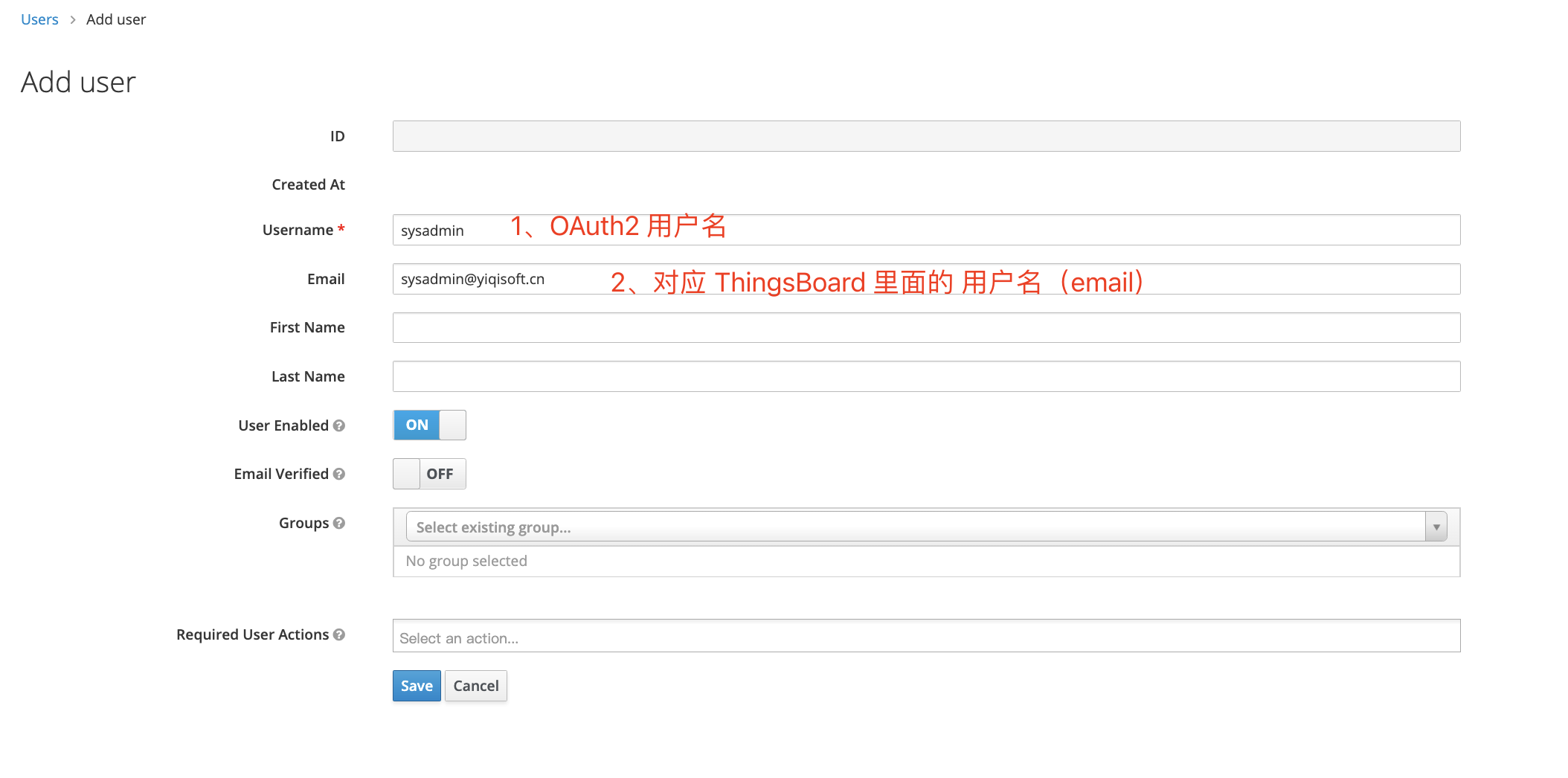
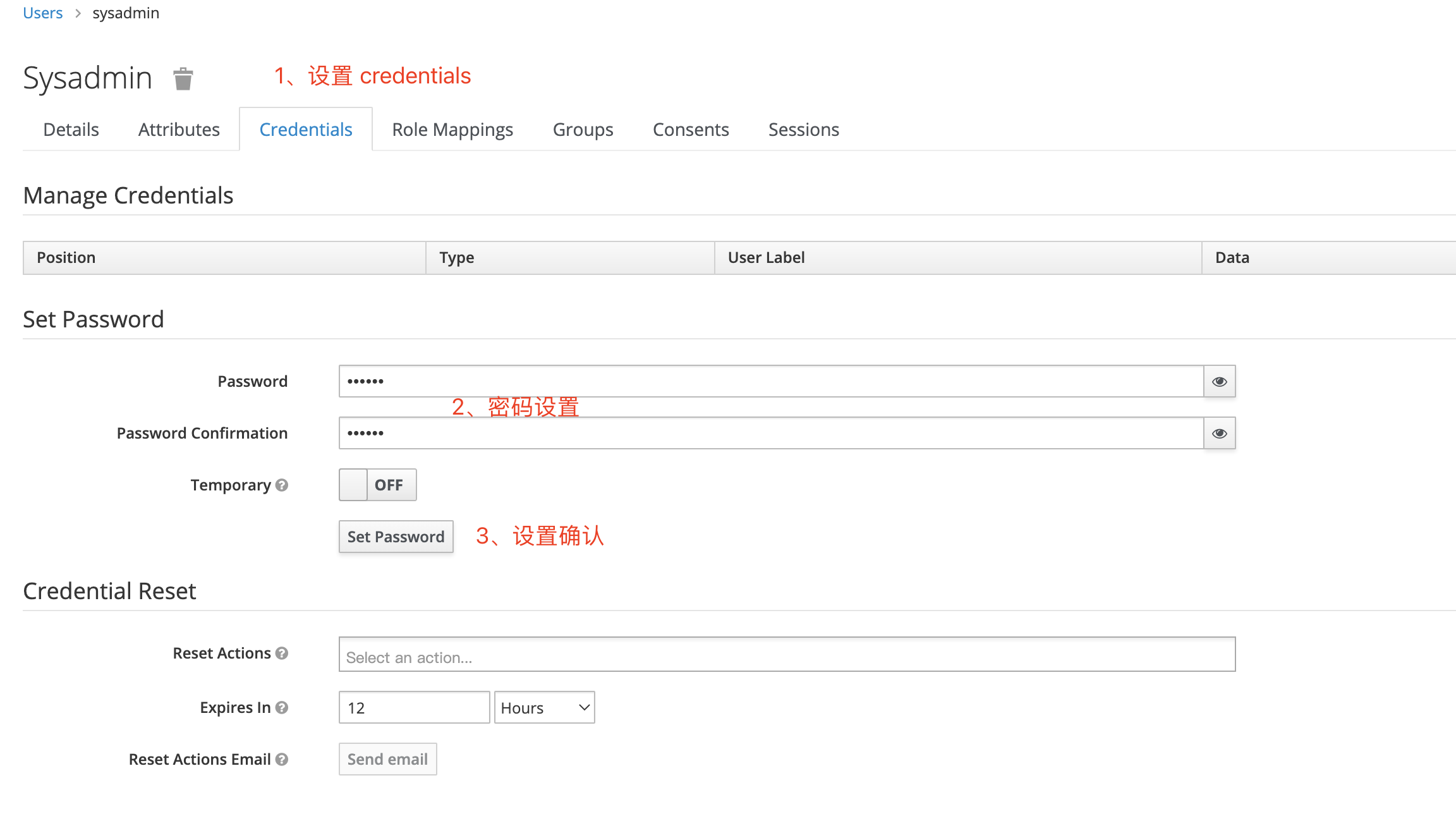
设置 user 密码
2.2、ThingsBoard 配置
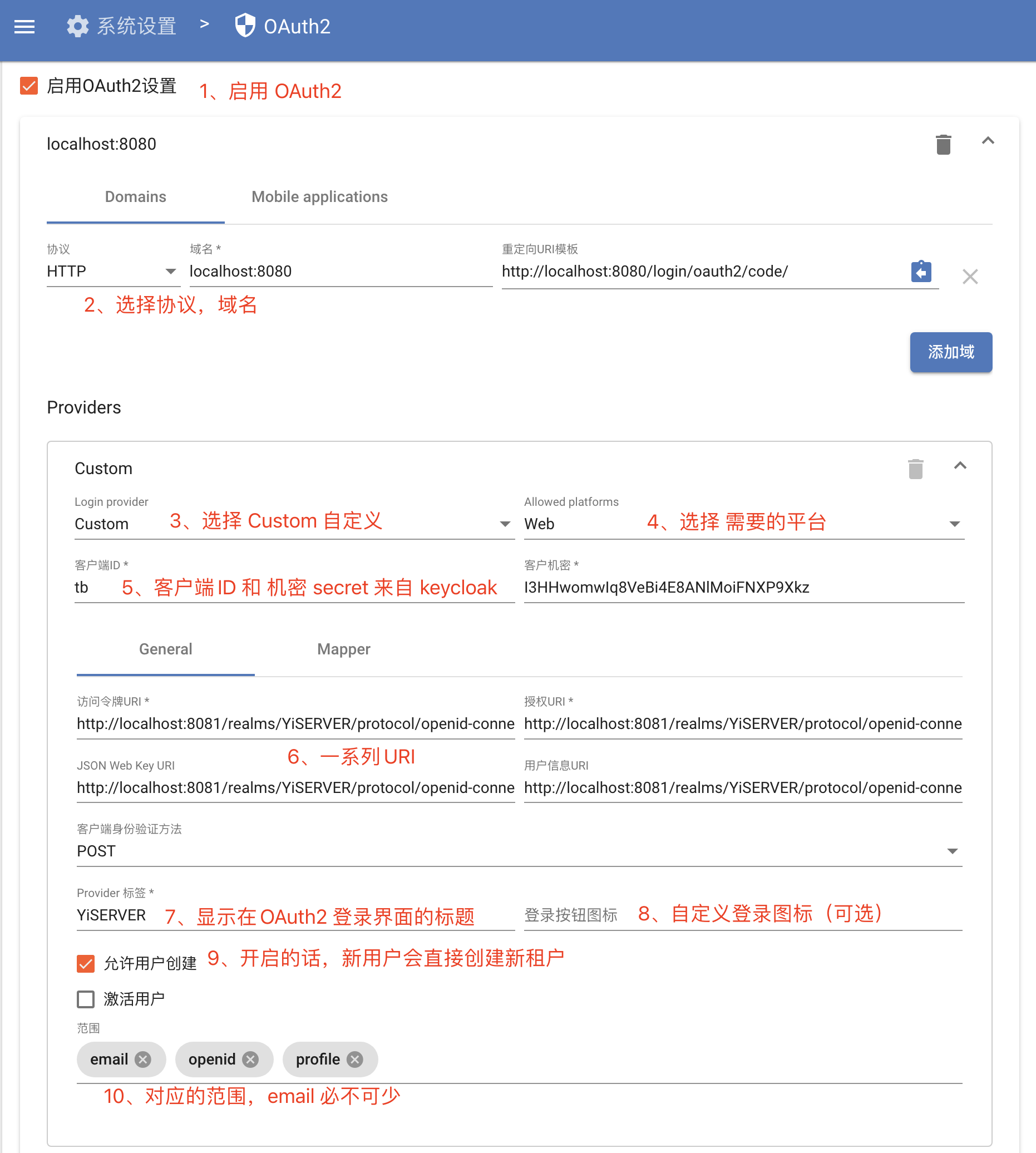
尤其注意 一系列 URI,其中 YiSERVER 换成你的 真实 realm 即可。
访问令牌URI:
http://localhost:8081/realms/YiSERVER/protocol/openid-connect/token
授权URI:
http://localhost:8081/realms/YiSERVER/protocol/openid-connect/auth
JSON Web Key URI:
http://localhost:8081/realms/YiSERVER/protocol/openid-connect/certs
用户信息URI:
http://localhost:8081/realms/YiSERVER/protocol/openid-connect/userinfo
3、验证
3.1、登录 ThingsBoard
3.2、跳转到 Keycloak
3.3、完成 OAuth2 登录集成