方案|如何使用 Intel Extension for PyTorch (IPEX) 在 iGPU/dGPU 上训练 YOLO 模型
使用 Intel Extension for PyTorch (IPEX) 训练
YOLO模型可以显著提升在 Intel 硬件(如 CPU 和 GPU)上的性能。以下是一个详细的步骤指南,帮助你结合 IPEX 优化和加速YOLO模型的训练过程。
演示视频
系统要求
硬件要求
本文中,我们使用 Intel® Arc™ A770 独立显卡和 Ultra 7 内置的 Intel(R) Arc(TM) Graphics 显卡。
官方推荐的并验证过的显卡如下:
- Intel® Arc™ A-Series Graphics (Intel® Arc™ A770 [Verified], Intel® Arc™ A750, Intel® Arc™ A580, Intel® Arc™ A770M, Intel® Arc™ A730M, Intel® Arc™ A550M)
- Intel® Data Center GPU Max Series [Verified]
- Intel® Data Center GPU Flex Series 170 [Verified]
软件要求
本文使用 Ubuntu 22.04 操作系统,并在 Kubernetes 集群进行分布式训练。当然,你可以使用其他操作系统或分布式训练框架,但需要确保你的系统满足 IPEX 的硬件和软件要求。其中,比较重要的是满足硬件驱动要求。
- Python: 3.9 或更高版本
- 如果使用 Jupyter Notebook 进行训练,需要安装
Jupyter Notebook和JupyterLab;
环境准备
了解 Intel Extension for PyTorch (IPEX)
按照 Intel 官方说明:A Python package for extending the official PyTorch that can easily obtain performance on Intel platform,英特尔® PyTorch 扩展程序通过最新的功能优化扩展了 PyTorch,从而在英特尔硬件上进一步提升性能。这些优化充分利用了英特尔 CPU 上的英特尔® 高级矢量扩展 512(英特尔® AVX-512)矢量神经网络指令 (VNNI) 和英特尔® 高级矩阵扩展(英特尔® AMX),以及英特尔独立 GPU 上的英特尔 Xe 矩阵扩展 (XMX) AI 引擎。此外,英特尔® PyTorch 扩展程序还通过 PyTorch xpu 设备为英特尔独立 GPU 提供轻松的 GPU 加速。
- GitHub 仓库:https://github.com/intel/intel-extension-for-pytorch
- 官方文档:https://intel.github.io/intel-extension-for-pytorch/
- Docker 镜像:https://hub.docker.com/r/intel/intel-extension-for-pytorch
[推荐]使用 Intel Extension for PyTorch (IPEX) 容器
使用 Jupyter Notebook 进行训练(Docker)
这种方法适合自己测试,比如在 Intel AIPC 上进行训练测试。
-
运行 XPU Jupyter Notebook 容器
docker run -it --rm \ -p 8888:8888 \ --device /dev/dri \ -v /dev/dri/by-path:/dev/dri/by-path \ intel/intel-extension-for-pytorch:2.6.10-xpu-pip-jupyter -
访问 Jupyter Notebook
http://localhost:8888/
使用 Kubeflow 进行分布式训练(Kubernetes)
- 在 Kubernetes 上部署 Kubeflow
这个步骤相对比较复杂,可以参考 Kubeflow 官方文档:https://www.kubeflow.org/docs/started/installing-kubeflow/
- 在 Kubeflow 上部署 IPEX 训练任务
创建一个 Notebook,使用自定义的 Custom Image,例如提前下载 Image 到本地 Registry:hub.yiqisoft.cn/intel/intel-extension-for-pytorch:2.6.10-xpu-pip-jupyter,需要分配至少 4个 CPU 核心和 8GB 内存,否则跑最基本的训练任务都会出现 OOM 内存溢出导致训练失败。
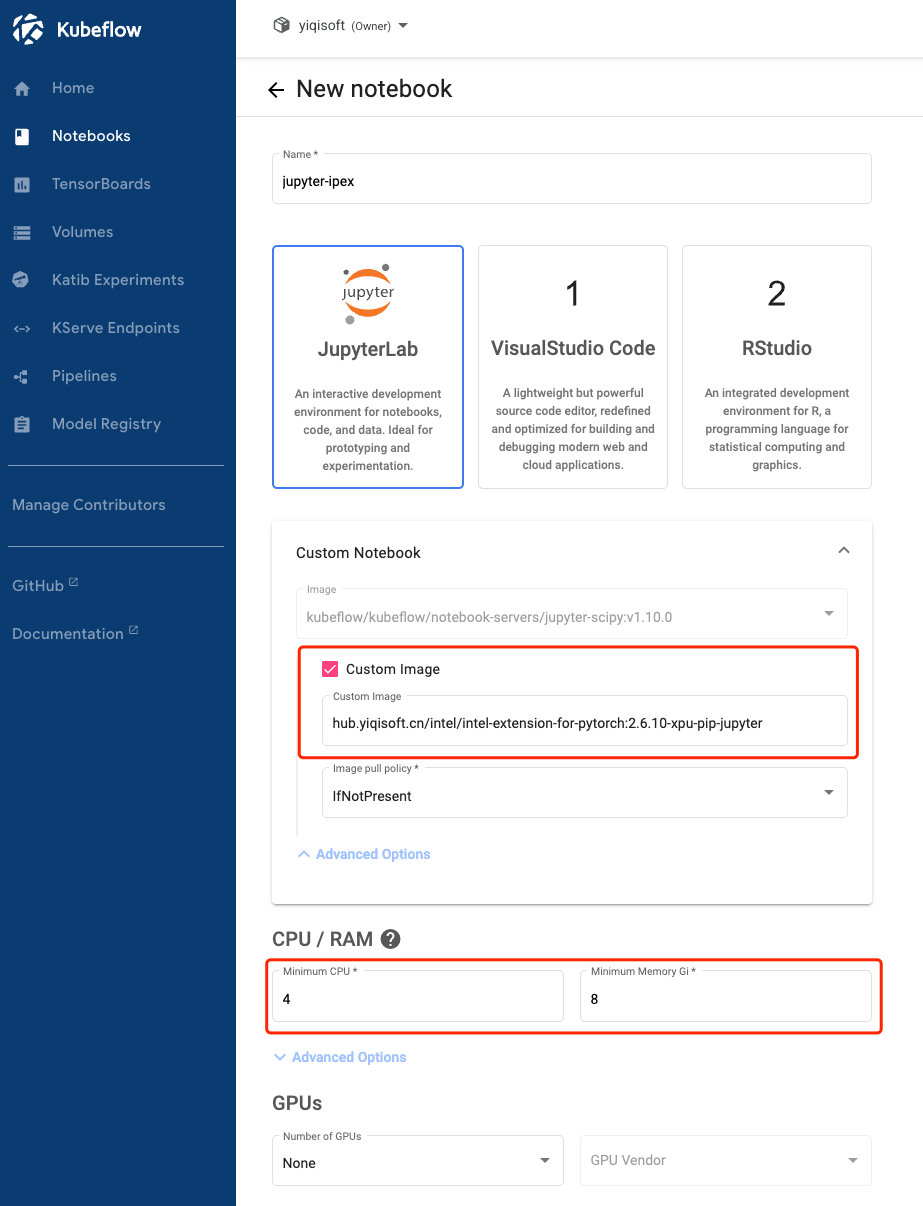
部署成功后,就可以启动 Notebook 进行训练了。
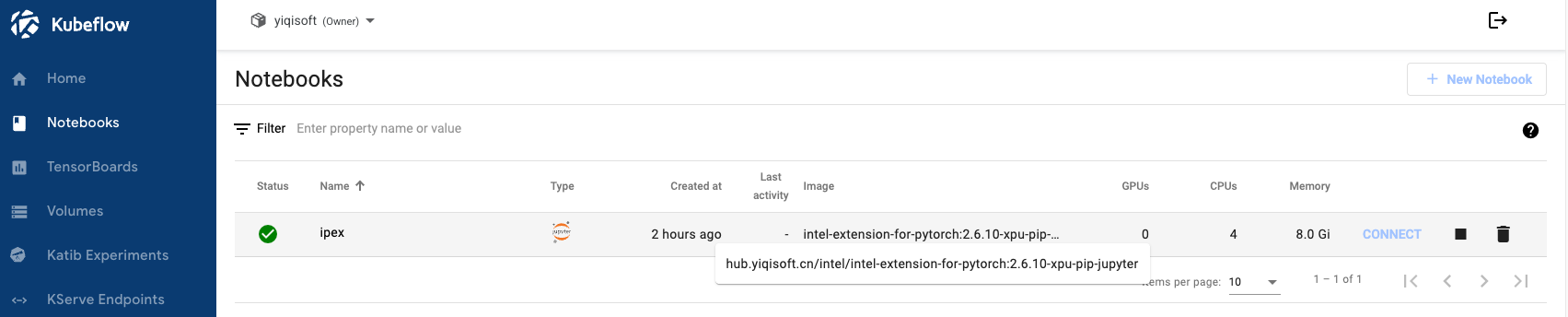
-
在 Kubernetes 上部署 Intel GPU device plugin for Kubernetes,以便 Kubernetes 可以识别到 GPU 设备。可以在以下链接找到文档:
https://github.com/intel/intel-device-plugins-for-kubernetes/blob/main/cmd/gpu_plugin/README.md -
修改 IPEX Notebook , 启用 i915 驱动,加入
gpu.intel.com/i915设备,并设置resources.limits.gpu.intel.com/i915为 1,表示使用 1 个 GPU 设备。如果是 Xe 系列的 GPU,则需要设置为gpu.intel.com/xe。spec: template: spec: containers: - env: [] image: >- hub.yiqisoft.cn/intel/intel-extension-for-pytorch:2.6.10-xpu-pip-jupyter imagePullPolicy: IfNotPresent name: ipex resources: limits: cpu: '4.8' gpu.intel.com/i915: 1 memory: 9.6Gi requests: cpu: '4' memory: 8Gi
提示
如果 PVC 采用 nfs 的话,需要在准备部署 Notebook 的 Node 主机上安装 nfs-common 包才能启动 pod。
- 连接 CONNECT ipex Notebook 后,即可使用
安装 Intel Extension for PyTorch (IPEX) 独立依赖包
如果不采用容器化部署的方式,还可以在系统中使用独立安装依赖包的方式。本文采用的是 XPU/GPU 方式,需要通过官方提供的方式进行安装相关依赖:https://pytorch-extension.intel.com/installation?request=platform,根据自己的硬件环境进行选择。
-
例如使用 pip 安装:
python -m pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/xpu python -m pip install intel-extension-for-pytorch==2.6.10+xpu oneccl_bind_pt==2.6.0+xpu --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/ -
安装完成后,可以使用以下命令验证安装是否成功:
python -c "import torch; import intel_extension_for_pytorch as ipex; print(torch.__version__); print(ipex.__version__); [print(f'[{i}]: {torch.xpu.get_device_properties(i)}') for i in range(torch.xpu.device_count())];" -
如果输出类似以下内容,则表示安装成功,这里显示
Intel(R) Arc(TM) Graphics显卡的详细信息:2.6.0+xpu 2.6.10+xpu [0]: _XpuDeviceProperties(name='Intel(R) Arc(TM) Graphics', platform_name='Intel(R) oneAPI Unified Runtime over Level-Zero', type='gpu', driver_version='1.6.32224+14', total_memory=59510MB, max_compute_units=128, gpu_eu_count=128, gpu_subslice_count=8, max_work_group_size=1024, max_num_sub_groups=128, sub_group_sizes=[8 16 32], has_fp16=1, has_fp64=1, has_atomic64=1)
准备数据集
数据集根据自已的需要进行准备:
- 本文使用 coco128 数据集,下载地址:https://docs.ultralytics.com/datasets/detect/coco128/,在使用 YOLO 进行训练时,会自动下载。
- 自定义数据集,需要满足 YOLO 训练数据集格式要求,参考:https://docs.ultralytics.com/datasets/detect/。
配置训练前准备
本文使用最简单的训练脚本来实现演示功能,可根据自身需要进行修改。参考:https://docs.ultralytics.com/modes/train/
安装操作系统依赖
由于默认的 IPEX 容器中没有安装操作系统依赖,需要手动安装,否则会报错。导致无法启动 YOLO 训练。
sed -i 's@//.*archive.ubuntu.com@//mirrors.ustc.edu.cn@g' /etc/apt/sources.list
apt update
apt install -y libgl1-mesa-dev libglib2.0-0
安装 YOLO 依赖
- 进入 Notebook 后,安装 YOLO 依赖,会依次安装 opencv、matplotlib、pandas、scikit-learn、seaborn、tqdm 等依赖包。
%pip install ultralytics
训练前准备
-
导入 YOLO 相关依赖
from ultralytics import YOLO import torch import intel_extension_for_pytorch as ipex device = torch.device('xpu' if torch.xpu.is_available() else 'cpu') print(device) -
提示
xpu表示使用 Intel GPU 进行训练。Creating new Ultralytics Settings v0.0.6 file ✅ xpu -
打印 GPU 设备信息
print("Has GPU: ",torch.xpu.has_xpu()) if (not torch.xpu.is_available()): print('Intel GPU not detected. Please install GPU with compatible drivers') sys.exit(1) print(torch.xpu.has_onemkl()) print(torch.__version__); print(ipex.__version__) [print(f'[{i}]: {torch.xpu.get_device_properties(i)}') for i in range(torch.xpu.device_count())] -
输出结果
Has GPU: True True 2.6.0+xpu 2.6.10+xpu [0]: _XpuDeviceProperties(name='Intel(R) Arc(TM) Graphics', platform_name='Intel(R) oneAPI Unified Runtime over Level-Zero', type='gpu', driver_version='1.6.32224+14', total_memory=59510MB, max_compute_units=128, gpu_eu_count=128, gpu_subslice_count=8, max_work_group_size=1024, max_num_sub_groups=128, sub_group_sizes=[8 16 32], has_fp16=1, has_fp64=1, has_atomic64=1)
训练模型
本文使用 yolov8n 模型进行训练,参考:https://docs.ultralytics.com/models/yolov8/,你也可以使用其他版本进行训练过程。
-
加载模型
model = YOLO('yolov8n.pt').to(device) -
使用 IPEX 优化模型
model = ipex.optimize(model) -
训练模型:这里使用 coco128 数据集进行训练,使用 2 个 epoch 进行训练,imgsz 设置为 640,workers 设置为 1。
results = model.train( data="coco128.yaml", epochs=2, imgsz=640, device=device, amp=False, workers=1 ) -
训练过程监控,2 epoch 训练过程、GPU内存使用情况、训练时间、训练后模型保存位置、以及各种指标。
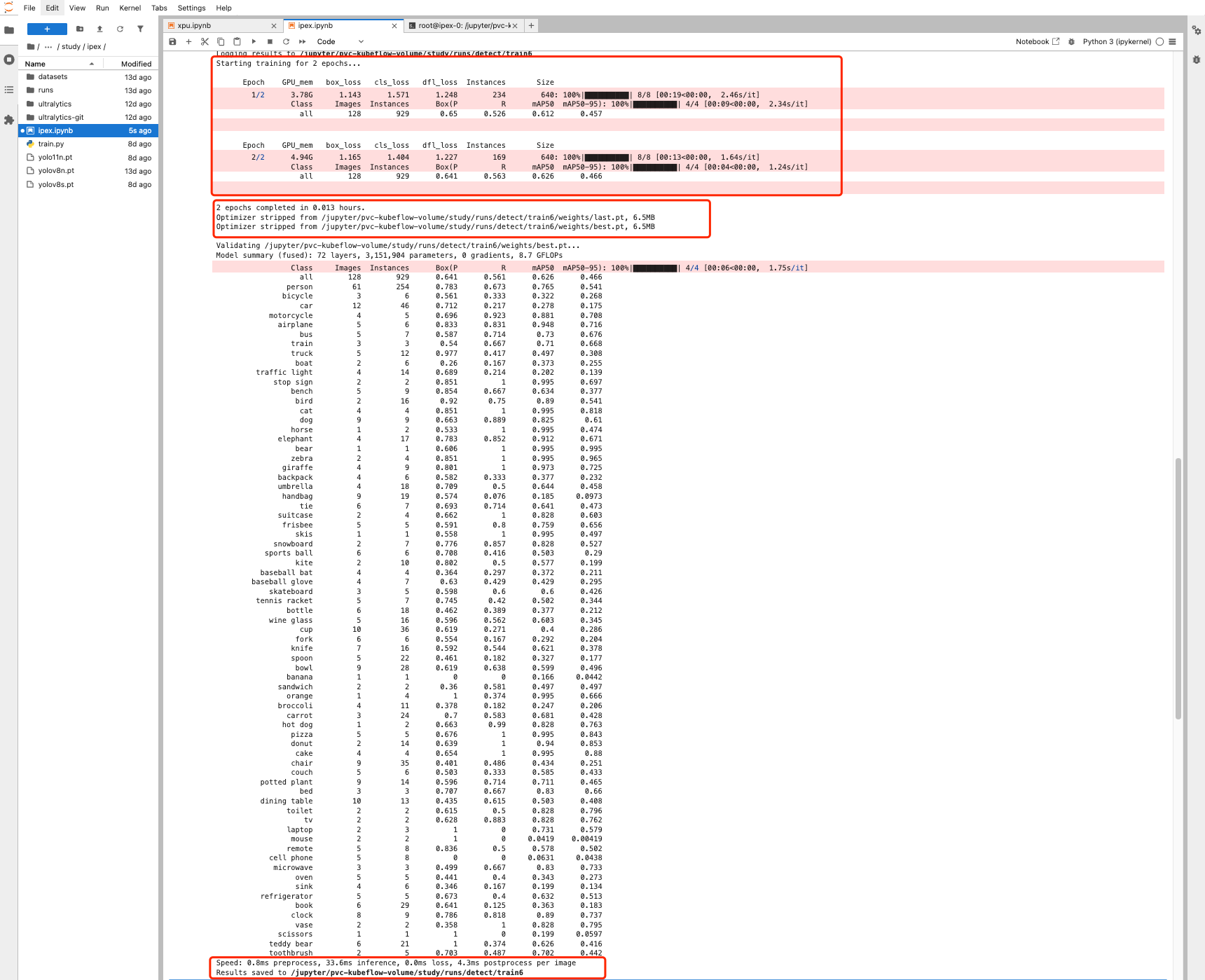
- 训练过程中,GPU 状态监控,可以看到 GPU 内存使用情况、GPU 使用率、GPU 主频等信息可以通过
intel-gpu-top进行查看。

提示
以下内容将在后续章节中进行详细介绍。敬请期待!
评估模型性能
这部分属于高阶内容,可以使用 Kubeflow 进行模型评估,也可以使用 TensorBoard 进行模型评估,或者使用其他方式进行模型评估,这里不做详细介绍。
模型自动化迭代训练
- 通过 Kubeflow 的 Pipeline 功能,可以实现模型的自动化迭代训练;
- 通过 Kubeflow 的 TensorBoard 功能,可以实现模型的可视化监控;
- 通过 Kubeflow 的 Model Registry 功能,可以实现模型的版本管理;
- 通过 Kubeflow 的 CI/CD 功能,可以实现模型的自动化部署;