构建本地化 AI 生产力:基于双 Intel Arc B580 与 QwenPaw 驱动 Gemma-4-26B 的万元级整机方案
在很长一段时间里,大语言模型(LLM)的“高性能”与“本地化”似乎是一对互斥的概念。
当我们谈论像 Gemma-4-26B 这样具备深度逻辑推理能力的模型时,脑海中浮现的往往是昂贵的 NVIDIA H100 集群,或者是动辄数万元的消费级旗舰显卡。这种“算力门槛”无形中划定了一道界限:高性能的 AI 智能体似乎是属于少数人的奢侈品,而普通开发者和企业只能在云端 API 的限制与本地轻量化模型(如 4B、7B)的智力瓶颈之间艰难权衡。
然而,技术演进的魅力往往在于“边界的移动”。
随着 llama.cpp 对多硬件生态的持续兼容,以及 Intel Arc 系列显卡在 OneAPI 架构下的潜力释放,我开始思考一个问题:
如果我们将目光从昂贵的垄断生态转向更具性价比的硬件组合,是否能够通过精妙的软件工程,实现一种“智力与成本”的动态平衡?
这篇技术文章,本质上是我的一次实验记录。
我试图用一套“万元级”的整机方案,通过双 Intel Arc B580 显卡构建起足以支撑重量级模型的显存空间,并利用 QwenPaw 框架将模型的能力从“对话”转化为“行动”。我并不想仅仅展示如何搭建一台机器,我更想展示一种可能性:
通过合理的硬件选型与高效的软件栈组合,我们完全可以在本地,构建起一个既强大、又私密、且具备真实生产力的 AI 智能体中心。
这不仅是一次关于硬件的组装,更是一次关于“如何让高智力 AI 走进现实生产力”的探索。
目录
1. 引言
随着大语言模型(LLM)技术的爆发,AI 的应用范式正在经历一场深刻的变革:从简单的“云端对话框”向具备自主规划、工具调用能力的“本地化 Agent(智能体)”转型。对于开发者和企业而言,这种转型面临着一个核心矛盾:高智力模型对显存的渴求与高性能硬件高昂成本之间的冲突。
通常,要流畅运行参数量在 20B 以上、具备逻辑推理能力的模型,往往意味着必须投入昂贵的 NVIDIA 高端显卡。然而,随着 Intel Arc 系列显卡在计算生态(尤其是 OneAPI 环境下)的不断成熟,以及 llama.cpp 等高效推理框架对多硬件平台的深度优化,我们迎来了一个全新的机会窗口——利用极致的性价比,实现“生产力级”的本地 AI 部署。
本文将详细记录一套完整的工程实践方案:我们通过构建一套万元级整机,利用双 Intel Arc B580 显卡(12G*2=24G)构建显存池,配合高性能推理后端 llama.cpp,驱动重量级模型 Gemma-4-26B。更重要的是,我们通过 QwenPaw 框架,将这个强大的模型从单纯的“聊天机器人”转化为一个能够真正处理任务、调用工具的本地化 AI 私人助理。
我们将从硬件选型、Docker 容器化部署、OneAPI 环境配置,到最终的 Agent 能力集成,全方位展示如何用最合理的成本,构建起属于自己的、安全且强大的本地 AI 生产力中心。
2. 系统架构设计:构建三位一体的本地 AI 栈
在设计这套本地化 AI 系统时,我们面临的挑战并非简单的“模型运行”,而是一个复杂的异构计算调度问题。要实现一个既具备高智力(Reasoning)、又具备高响应(Responsiveness)、且具备实际行动力(Actionability)的智能体,必须构建一个高度协同的“三位一体”架构。
我们将整个系统抽象为三个逻辑层:硬件层(计算底座)、推理层(逻辑中枢)与智能体层(执行灵魂)。
2.1 硬件层:基于双 Intel Arc B580 的显存池化策略 (The Body)
对于 20B 以上参数规模的模型,硬件设计的核心矛盾在于“显存墙 (VRAM Wall)”。
在消费级硬件生态中,单张显卡的显存容量往往是制约模型规模的绝对瓶颈。如果显存不足,模型不得不频繁地在系统内存(System RAM)与显存(VRAM)之间进行交换,这将导致推理速度出现数量级的下降。
我们的设计思路是:通过“显存池化 (VRAM Pooling)”实现容量突破。
通过使用两张 Intel Arc B580 显卡,我们并没有简单地将它们视为两个独立的计算单元,而是通过底层的 PCIe 总线和 llama.cpp 的分布式张量管理,在逻辑上构建了一个统一的、大容量的显存空间。这种设计允许我们将 Gemma-4-26B 的全部权重(Weights)完全卸载(Offload)到 GPU 显存中,从而彻底规避了由于内存交换带来的带宽瓶颈,确保了推理过程中的高吞吐量。
工程洞察 (Engineering Insight): 这种“以量换质”的策略,其核心在于利用双卡的显存容量红利,换取了运行重量级模型所需的“入场券”。对于 26B 规模的模型,这种方案在万元级整机预算内,提供了极高的性价比。
2.2 推理层:基于 llama.cpp 的异构计算调度 (The Brain)
如果说硬件提供了物理空间,那么推理层则是决定计算效率的核心。我们选择了 llama.cpp 作为推理引擎,其背后的设计哲学是“极致的计算卸载与异构调度”。
在我们的架构中,推理层承担了两个关键任务:
-
张量切分与并行计算 (Tensor Splitting & Parallelism): 这是实现双卡协同的技术核心。
llama.cpp利用tensor-split技术,将模型每一层的计算任务进行切分,并将不同的张量分发到两张 B580 显卡上。通过 Intel OneAPI (Level Zero) 后端,计算指令被精准地发送至 GPU 的执行单元(EU),实现了计算压力的分布式卸载。 -
CPU 与 GPU 的协同调度 (CPU-GPU Orchestration): 在异构计算中,CPU 不仅仅是“管理者”,更是“预处理器”。在我们的实测中,CPU 负责处理 Tokenization(分词)、Sampling(采样策略)以及复杂的逻辑分支判断,而将繁重的矩阵乘法 (GEMM) 运算完全交给 GPU。这种“计算重心向 GPU 偏移”的策略,使得 CPU 即使在非顶级配置下,也能通过高效的调度,实现极低的推理延迟。
2.3 智能体层:基于 QwenPaw 的 ReAct 认知循环 (The Soul & Hands)
一个仅仅能“预测下一个 Token”的模型,本质上是一个静态的概率引擎,它缺乏与现实世界交互的能力。为了将 Gemma-4 从“聊天机器人”进化为“私人助理”,我们需要引入 QwenPaw 来构建认知循环。
我们采用了业界领先的 ReAct (Reasoning and Acting) 模式。在 QwenPaw 的驱动下,系统的运行逻辑从“输入 → 输出”转变为“思考 → 行动 → 观察 → 总结”的闭环循环:
- Reasoning (思考):当用户发出复杂指令时,QwenPaw 驱动模型进行逻辑拆解,生成下一步的计划。
- Acting (行动):模型通过 Function Calling 机制,输出特定的工具调用指令。QwenPaw 捕获这些指令,并在本地环境中执行对应的操作(如读取文件、执行脚本、查询数据库)。
- Observation (观察):执行结果被反馈给模型,模型将其作为新的上下文信息。
- Final Response (总结):模型基于观察到的反馈,完成任务并给出最终答案。
通过这一层架构,我们成功地将底层的算力与模型能力,转化为了具备任务执行力的智能体逻辑。
3. 硬件选型与环境预备
在构建本地 AI 生产力工具时,工程师面临的核心挑战是如何在预算约束与性能需求之间找到最优解。这不仅仅是一个“买什么”的问题,更是一个“如何组合”的问题。
3.1 硬件决策矩阵:性价比与显存容量的权衡
在选择 GPU 时,我们必须跳出传统的“单卡性能”思维,转向“显存容量/成本比”的维度。
对于 Gemma-4-26B 这样规模的模型,其量化后的权重文件通常占据了大量的显存空间。如果单卡显存不足,系统将不得不依赖系统内存(System RAM)进行数据交换,这会产生巨大的 PCIe 带宽延迟,导致推理速度从“实时交互”降级为“逐字蹦出”。
为什么选择双 Intel Arc B580?
- 显存容量红利:通过双卡组合,我们以极低的成本获得了足以承载 26B 模型的显存空间。
- 架构优势:Intel Arc 系列在 OneAPI 生态下的算子优化正在快速迭代,尤其是在处理大规模矩阵运算时,展现出了极高的性价比。
- 成本控制:相比于购买单张高显存的 NVIDIA 专业级显卡,使用两张中端 B580 构建的“显存池化”方案,将整机成本控制在了万元量级,这使得“本地化高性能 AI”从实验室走向了个人开发者和中小企业的桌面。
3.2 性能观察:CPU 的“过度配置”与计算重心转移
在本次实验的参考配置中,我们使用了 Intel Ultra 9 285K 处理器配合 48GB DDR5 内存。然而,通过对系统运行时的实时监控,我们发现了一个非常具有工程指导意义的现象:
推理过程中的 CPU 负载呈现出高度的“非对称性”。
在模型进行密集推理时,CPU 的整体利用率并不高,大部分核心处于闲置或低负载状态,仅有 1-2 个核心 处于高活跃度。这印证了我们在架构设计中的预判:在成熟的 llama.cpp 调度机制下,计算重心已经高度向 GPU 侧偏移。
💡 工程优化建议 (Engineering Recommendations): 基于这一观察,我们可以得出结论:构建该方案并不需要追求顶级的 CPU 性能。
- CPU 选型:对于追求极致性价比的玩家,使用 i5 或 i7 级别的处理器 完全能够胜任指令调度与数据预处理的工作。
- 内存配置:32GB 内存 已足以满足系统运行与模型预加载的需求,无需盲目追求超大容量。
- 结论:通过将预算从 CPU 转向 GPU(即增加显卡数量或提升显卡规格),可以获得更显著的推理性能增益。
3.3 软件底座:构建稳定的计算环境
硬件只是骨架,软件栈才是驱动系统的血液。为了确保计算任务能稳定地从 CPU 卸载到 GPU,我们需要构建一套完整的软件生态。
3.3.1 驱动与计算运行时 (The Runtime Stack)
核心在于 Intel OneAPI 及其底层的 Level Zero 接口。
- Level Zero:它是 Intel 提供的一种高性能、低开销的硬件抽象层,直接面向 GPU 硬件进行指令调度。它是
llama.cpp实现高性能计算卸载的基石。 - 驱动版本:必须确保 Linux 内核驱动与 OneAPI 运行时版本高度匹配,任何版本上的细微偏差都可能导致多卡间的通信失败或显存分配异常。
3.3.2 操作系统与容器化策略 (OS & Containerization)
- 操作系统:我们选择了 Linux (Ubuntu) 作为基座。Linux 在处理底层硬件驱动、显卡透传以及内存管理方面,比 Windows 具有更高的稳定性和更低的开销。
- 容器化 (Docker):为了避免复杂的依赖冲突(例如 OneAPI 库的版本管理),我们采用了 Docker 进行全栈部署。通过将驱动、运行时与推理引擎封装在容器内,我们实现了“环境即代码”的工程目标,极大地提高了方案的可移植性与复用性。
4. 核心部署实践:容器化推理后端
在生产环境中,手动配置驱动、依赖库和模型路径不仅效率低下,且极易造成环境污染。我们采用 Docker Compose 作为编排工具,将 llama.cpp 的运行环境完全隔离,实现“一键式”部署。
4.1 容器化部署策略:环境即代码
我们使用的镜像 hub.yiqisoft.cn/ggml-org/llama.cpp:server-intel 是专门针对 Intel GPU 进行了深度预编译的镜像,内置了完整的 OneAPI 运行时环境。这种“预集成”的策略极大地降低了用户在配置 Level Zero 驱动时的出错概率。
以下是我们在本项目中使用的核心配置文件:
services:
llama-cpp:
image: hub.yiqisoft.cn/ggml-org/llama.cpp:server-intel
container_name: llama
privileged: true # 授予容器访问底层硬件设备的最高权限
restart: unless-stopped
shm_size: '16g' # 关键:为多卡间的高速通信预留足够的共享内存
devices:
- /dev/dri:/dev/dri # 将宿主机的 Direct Rendering Infrastructure 设备透传进容器
ports:
- "8080:8080"
volumes:
- ~/models/gemma-4-26b-gguf:/models
environment:
- ONEAPI_DEVICE_SELECTOR=level_zero:0,1 # 显式指定启用两个 Intel GPU 实例
command: >
-m /models/gemma-4-26B-A4B-it-UD-Q4_K_M.gguf
--host 0.0.0.0
--port 8080
-c 131072
--tensor-split 0.5,0.5
-ngl 99
-b 1024
--metrics
4.2 关键参数的工程深度解析
仅仅运行容器是不够的,要发挥双显卡的极致性能,必须对以下关键参数进行深度调优:
1. 硬件透传与权限管理 (privileged & devices)
在 Linux 环境下,显卡设备通常由 /dev/dri 下的字符设备文件管理。通过 devices 映射,我们将宿主机的显卡驱动接口暴露给容器。同时,由于 OneAPI 在进行跨设备内存分配时需要较高的系统调用权限,设置 privileged: true 是确保底层驱动能正确接管硬件计算任务的关键。
2. 共享内存与多卡通信 (shm_size)
这是许多初学者容易忽略的致命陷阱。在单卡模式下,默认的共享内存(通常为 64MB)绰绰有余;但在双卡模式下,llama.cpp 需要通过共享内存进行张量(Tensor)的快速交换与同步。如果 shm_size 设置过小,会导致容器在进行多卡计算时由于内存溢出(OOM)而直接崩溃。我们将此值设置为 16g,为高并发的通信预留了充足的缓冲。
3. 显存池化的核心指令 (ONEAPI_DEVICE_SELECTOR & --tensor-split)
这是实现“显存合并”的灵魂:
ONEAPI_DEVICE_SELECTOR=level_zero:0,1:这是 Intel 运行时环境的指令,它强制要求引擎识别并加载两个 Level Zero 设备。--tensor-split 0.5,0.5:这是llama.cpp的精髓。它告诉推理引擎,将每一层模型的权重均匀地切分为两份,分别放置在两张显卡的显存中。通过这种方式,我们将两张显卡的容量在逻辑上实现了“合二为一”。
4. 推理性能优化 (-ngl, -c, -b)
-ngl 99(Number of GPU Layers):我们将这个值设为 99(远超模型实际层数,根据模型的实际值选择一个数字,比如:75,85等),目的是确保模型的所有层都被完全卸载(Offload)到 GPU 上,彻底消除 CPU 计算带来的延迟。-c 131072(Context Size):支持高达 128K 的上下文长度。这对于 Agent 处理长文档或维持长对话记忆至关重要,但也对显存提出了极高的要求,这也正是我们采用双卡方案的意义所在,根据对话次数的多少,选择(65536-131072-262144)之间的合适值。-b 1024(Batch Size):通过增大 Batch Size,我们提升了 GPU 在处理 Prompt 阶段的吞吐量,实现了更快的首字响应速度(Time to First Token),可根据自己的实际需求改成(512-768-1024)区间里的一个最合适的值。
4.3 可观测性:监控与调试 (--metrics)
在生产环境下,我们无法仅凭“感觉”来判断系统是否运行正常。通过在 command 中添加 --metrics 参数,llama.cpp 会在 8080 端口暴露一个 Prometheus 格式的监控接口。这允许我们实时观察显存占用、Token 生成速率以及计算延迟,为后续的性能调优提供量化的数据支持。也是为 Prometheus 和 Grafana Dashboard 做准备。
通过 http://192.168.123.57:8080/metrics 获取到 llama.cpp 服务的 metrics:
# HELP llamacpp:prompt_tokens_total Number of prompt tokens processed.
# TYPE llamacpp:prompt_tokens_total counter
llamacpp:prompt_tokens_total 164913
# HELP llamacpp:prompt_seconds_total Prompt process time
# TYPE llamacpp:prompt_seconds_total counter
llamacpp:prompt_seconds_total 757.063
# HELP llamacpp:tokens_predicted_total Number of generation tokens processed.
# TYPE llamacpp:tokens_predicted_total counter
llamacpp:tokens_predicted_total 18804
# HELP llamacpp:tokens_predicted_seconds_total Predict process time
# TYPE llamacpp:tokens_predicted_seconds_total counter
llamacpp:tokens_predicted_seconds_total 587.57
# HELP llamacpp:n_decode_total Total number of llama_decode() calls
# TYPE llamacpp:n_decode_total counter
llamacpp:n_decode_total 18996
# HELP llamacpp:n_tokens_max Largest observed n_tokens.
# TYPE llamacpp:n_tokens_max counter
llamacpp:n_tokens_max 37027
# HELP llamacpp:n_busy_slots_per_decode Average number of busy slots per llama_decode() call
# TYPE llamacpp:n_busy_slots_per_decode counter
llamacpp:n_busy_slots_per_decode 1.00463
# HELP llamacpp:prompt_tokens_seconds Average prompt throughput in tokens/s.
# TYPE llamacpp:prompt_tokens_seconds gauge
llamacpp:prompt_tokens_seconds 217.833
# HELP llamacpp:predicted_tokens_seconds Average generation throughput in tokens/s.
# TYPE llamacpp:predicted_tokens_seconds gauge
llamacpp:predicted_tokens_seconds 32.003
# HELP llamacpp:requests_processing Number of requests processing.
# TYPE llamacpp:requests_processing gauge
llamacpp:requests_processing 0
# HELP llamacpp:requests_deferred Number of requests deferred.
# TYPE llamacpp:requests_deferred gauge
llamacpp:requests_deferred 0
4.4 日志运行情况监控(Docker logs)
通过命令行:docker logs -t -f llama-cpp 可以实时观测 容器运行情况:
2026-05-04T00:46:21.732218669Z load_backend: loaded SYCL backend from /app/libggml-sycl.so
2026-05-04T00:46:21.748791856Z load_backend: loaded CPU backend from /app/libggml-cpu-alderlake.so
2026-05-04T00:46:21.749464099Z warn: LLAMA_ARG_HOST environment variable is set, but will be overwritten by command line argument --host
2026-05-04T00:46:21.750775937Z main: n_parallel is set to auto, using n_parallel = 4 and kv_unified = true
2026-05-04T00:46:21.750783127Z build_info: b8994-aab68217b
2026-05-04T00:46:21.750784510Z system_info: n_threads = 4 (n_threads_batch = 4) / 24 | CPU : SSE3 = 1 | SSSE3 = 1 | AVX = 1 | AVX_VNNI = 1 | AVX2 = 1 | F16C = 1 | FMA = 1 | BMI2 = 1 | LLAMAFILE = 1 | OPENMP = 1 | REPACK = 1 |
2026-05-04T00:46:21.750786270Z Running without SSL
2026-05-04T00:46:21.750787020Z init: using 23 threads for HTTP server
2026-05-04T00:46:21.750827662Z start: binding port with default address family
2026-05-04T00:46:21.752338980Z main: loading model
2026-05-04T00:46:21.752357820Z srv load_model: loading model '/models/gemma-4-26B-A4B-it-UD-Q4_K_M.gguf'
2026-05-04T00:46:21.752359446Z common_init_result: fitting params to device memory, for bugs during this step try to reproduce them with -fit off, or provide --verbose logs if the bug only occurs with -fit on
2026-05-04T00:46:21.752360484Z common_params_fit_impl: getting device memory data for initial parameters:
2026-05-04T00:46:22.116450365Z common_memory_breakdown_print: | memory breakdown [MiB] | total free self model context compute unaccounted |
2026-05-04T00:46:22.116475633Z common_memory_breakdown_print: | - SYCL0 (Intel(R) Arc(TM) B580 Graphics) | 12216 = 11619 + (11006 = 8162 + 1528 + 1315) + -10409 |
2026-05-04T00:46:22.116477174Z common_memory_breakdown_print: | - SYCL1 (Intel(R) Arc(TM) B580 Graphics) | 12216 = 11796 + (10947 = 7908 + 1932 + 1106) + -10528 |
2026-05-04T00:46:22.116478082Z common_memory_breakdown_print: | - Host | 1819 = 748 + 0 + 1071 |
2026-05-04T00:46:22.173009963Z common_params_fit_impl: projected memory use with initial parameters [MiB]:
2026-05-04T00:46:22.173046467Z common_params_fit_impl: - SYCL0 (Intel(R) Arc(TM) B580 Graphics): 12216 total, 11006 used, 613 free vs. target of 1024
2026-05-04T00:46:22.173049673Z common_params_fit_impl: - SYCL1 (Intel(R) Arc(TM) B580 Graphics): 12216 total, 10947 used, 848 free vs. target of 1024
2026-05-04T00:46:22.173050989Z common_params_fit_impl: projected to use 21953 MiB of device memory vs. 23415 MiB of free device memory
2026-05-04T00:46:22.173052547Z common_params_fit_impl: cannot meet free memory targets on all devices, need to use 585 MiB less in total
2026-05-04T00:46:22.173053890Z common_params_fit_impl: context size set by user to 131072 -> no change
2026-05-04T00:46:22.174020411Z common_fit_params: failed to fit params to free device memory: n_gpu_layers already set by user to 85, abort
2026-05-04T00:46:22.174028393Z common_fit_params: fitting params to free memory took 0.42 seconds
2026-05-04T00:46:22.174051568Z llama_model_load_from_file_impl: using device SYCL0 (Intel(R) Arc(TM) B580 Graphics) (unknown id) - 11619 MiB free
2026-05-04T00:46:22.174056290Z llama_model_load_from_file_impl: using device SYCL1 (Intel(R) Arc(TM) B580 Graphics) (unknown id) - 11796 MiB free
2026-05-04T00:46:22.211279463Z llama_model_loader: loaded meta data with 60 key-value pairs and 658 tensors from /models/gemma-4-26B-A4B-it-UD-Q4_K_M.gguf (version GGUF V3 (latest))
2026-05-04T00:46:22.211300667Z llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
...
...
...
2026-05-04T04:37:34.904391258Z srv params_from_: Chat format: peg-gemma4
2026-05-04T04:37:34.904902053Z slot get_availabl: id 0 | task -1 | selected slot by LCP similarity, sim_best = 0.960 (> 0.100 thold), f_keep = 0.936
2026-05-04T04:37:34.904947009Z slot launch_slot_: id 0 | task -1 | sampler chain: logits -> ?penalties -> ?dry -> ?top-n-sigma -> top-k -> ?typical -> top-p -> min-p -> ?xtc -> ?temp-ext -> dist
2026-05-04T04:37:34.904950165Z slot launch_slot_: id 0 | task 23692 | processing task, is_child = 0
2026-05-04T04:37:34.904951439Z slot update_slots: id 0 | task 23692 | new prompt, n_ctx_slot = 131072, n_keep = 0, task.n_tokens = 28794
2026-05-04T04:37:34.904952845Z slot update_slots: id 0 | task 23692 | n_tokens = 27634, memory_seq_rm [27634, end)
2026-05-04T04:37:34.905861084Z slot update_slots: id 0 | task 23692 | prompt processing progress, n_tokens = 28278, batch.n_tokens = 644, progress = 0.982080
2026-05-04T04:37:38.681275445Z slot update_slots: id 0 | task 23692 | n_tokens = 28278, memory_seq_rm [28278, end)
2026-05-04T04:37:38.681395066Z slot update_slots: id 0 | task 23692 | prompt processing progress, n_tokens = 28790, batch.n_tokens = 512, progress = 0.999861
2026-05-04T04:37:38.896007651Z slot create_check: id 0 | task 23692 | created context checkpoint 19 of 32 (pos_min = 26250, pos_max = 28277, n_tokens = 28278, size = 396.118 MiB)
2026-05-04T04:37:41.832500456Z slot update_slots: id 0 | task 23692 | n_tokens = 28790, memory_seq_rm [28790, end)
2026-05-04T04:37:41.833966040Z slot init_sampler: id 0 | task 23692 | init sampler, took 1.51 ms, tokens: text = 28794, total = 28794
2026-05-04T04:37:41.833974615Z slot update_slots: id 0 | task 23692 | prompt processing done, n_tokens = 28794, batch.n_tokens = 4
2026-05-04T04:37:42.398503432Z slot create_check: id 0 | task 23692 | created context checkpoint 20 of 32 (pos_min = 26250, pos_max = 28789, n_tokens = 28790, size = 496.123 MiB)
2026-05-04T04:37:42.487963649Z srv log_server_r: done request: POST /v1/chat/completions 172.23.0.1 200
2026-05-04T04:37:42.518778388Z reasoning-budget: activated, budget=2147483647 tokens
2026-05-04T04:38:05.373961243Z reasoning-budget: deactivated (natural end)
2026-05-04T04:38:50.112852287Z slot print_timing: id 0 | task 23692 |
2026-05-04T04:38:50.112882771Z prompt eval time = 7579.87 ms / 1160 tokens ( 6.53 ms per token, 153.04 tokens per second)
2026-05-04T04:38:50.112884689Z eval time = 67627.82 ms / 1995 tokens ( 33.90 ms per token, 29.50 tokens per second)
2026-05-04T04:38:50.112885835Z total time = 75207.68 ms / 3155 tokens
2026-05-04T04:38:50.116294874Z slot release: id 0 | task 23692 | stop processing: n_tokens = 30788, truncated = 0
5. 赋予 Agent 灵魂:QwenPaw 深度集成
在许多人的认知中,大模型的使用仅仅停留在“问答”阶段。然而,在生产力场景下,用户需要的不是一个“百科全书”,而是一个“数字员工”。
单纯的模型(LLM)本质上是一个静态的概率预测引擎:它根据上下文预测下一个 Token,但它无法直接触达你的文件系统,无法操作你的终端,也无法感知外部世界的实时变化。要打破这种局限,我们需要引入 Agentic Workflow(智能体工作流)。
5.1 从 Chatbot 到 Agent:认知的升维
我们要实现的质变,在于从“对话模式”向“ReAct (Reasoning and Acting) 模式”的转变。
在传统的 Chatbot 模式下,交互是线性的:用户输入 → 模型输出。 而在 Agent 模式下,交互变成了一个动态的循环:思考 (Thought) → 行动 (Action) → 观察 (Observation) → 总结 (Final Answer)。
QwenPaw 在这个架构中的角色,正是这个循环的调度中枢。它负责维护 Agent 的“短期记忆”与“长期记忆”,并管理模型与外部工具(Tools)之间的交互协议。
5.2 技术集成:基于 OpenAI 兼容接口的桥接
实现集成的工程难点在于:如何让一个具备 Agent 能力的框架,与一个运行在 Docker 容器内的推理后端进行高效通信?
得益于 llama.cpp 对 OpenAI API 标准 的完美支持,集成过程变得异常优雅。我们不需要为 QwenPaw 编写复杂的底层驱动,只需要通过标准化的 HTTP 协议进行对接。
集成链路如下:
- 接口暴露:
llama.cpp在容器的8080端口上启动了一个兼容 OpenAI 规范的 API Server。 - 配置对接:在 QwenPaw 的配置文件中,我们将
base_url指向http://<host_ip>:8080/v1,并将模型名称指定为gemma-4-26b。 - 协议握手:QwenPaw 通过标准的 Chat Completion 接口发送 Prompt,并解析模型返回的结构化数据。
5.3 核心机制:Function Calling 与工具链闭环
这是赋予 Agent “双手”的关键技术。Gemma-4-26B 具备强大的逻辑推理能力,能够理解复杂的指令并识别出何时需要调用外部工具。
一个典型的 Agent 执行流示例:
用户指令:“帮我检查一下当前目录下
config.yaml的内容,并告诉我其中的端口号是多少。”
QwenPaw 驱动下的 ReAct 循环过程:
- Thought (思考):模型分析指令,意识到自己无法直接“看到”文件,需要调用
read_file工具。 - Action (行动):模型输出一个结构化的指令:
call: read_file(path="config.yaml")。 - Tool Execution (工具执行):QwenPaw 捕获该指令,在宿主机环境下执行文件读取操作。
- Observation (观察):QwenPaw 将读取到的文件内容(例如
port: 8080)作为“观察结果”重新喂给模型。 - Final Answer (总结):模型结合观察到的内容,得出结论:“
config.yaml中的端口号是 8080。”
通过这种机制,Gemma-4 不再是被困在文本世界里的“智者”,而是成为了一个能够跨越数字边界、操作物理环境的执行者。
5.4 深度观察:Agent 模式下的系统负载
在集成 QwenPaw 后,我们观察到系统的负载特征发生了微妙的变化。 由于 Agent 模式涉及多次“思考-行动-观察”的往返(Round-trip),系统的通信频率显著增加。虽然单次推理的计算量没有变化,但由于频繁的 Prompt 重构与上下文拼接,对内存带宽与网络延迟的要求变得更加敏感。
这也进一步证明了我们在第 3 章中选择高性能 DDR5 内存以及在第 4 章中优化 Docker 共享内存的必要性——只有构建了坚实的底层,Agent 的“思考循环”才能跑得足够流畅。
6. 性能实测与工程观察
在进行性能测试前,我们设定了一个基准场景:使用 Gemma-4-26B 模型,在 128K 上下文长度下,通过 QwenPaw 执行一系列涉及文件读取、逻辑推理与代码生成的复杂 Agent 任务。
6.1 推理速度与吞吐量 (Inference Throughput)
对于大模型应用,用户体验的核心指标有两个:首字延迟 (Time to First Token, TTFT) 与 生成速度 (Tokens Per Second, TPS)。
- TTFT (首字延迟):在处理长上下文 Prompt 时,由于
llama.cpp能够将大部分计算卸载至 GPU,我们的 TTFT 表现非常稳定,基本维持在秒级,这对于 Agent 的交互体验至关重要。 - TPS (生成速度):在双显卡并行模式下,Gemma-4-26B 的生成速度达到了令人满意的水平(实测约为
30-40tokens/s,此处根据实际测试数据可能有所变化)。
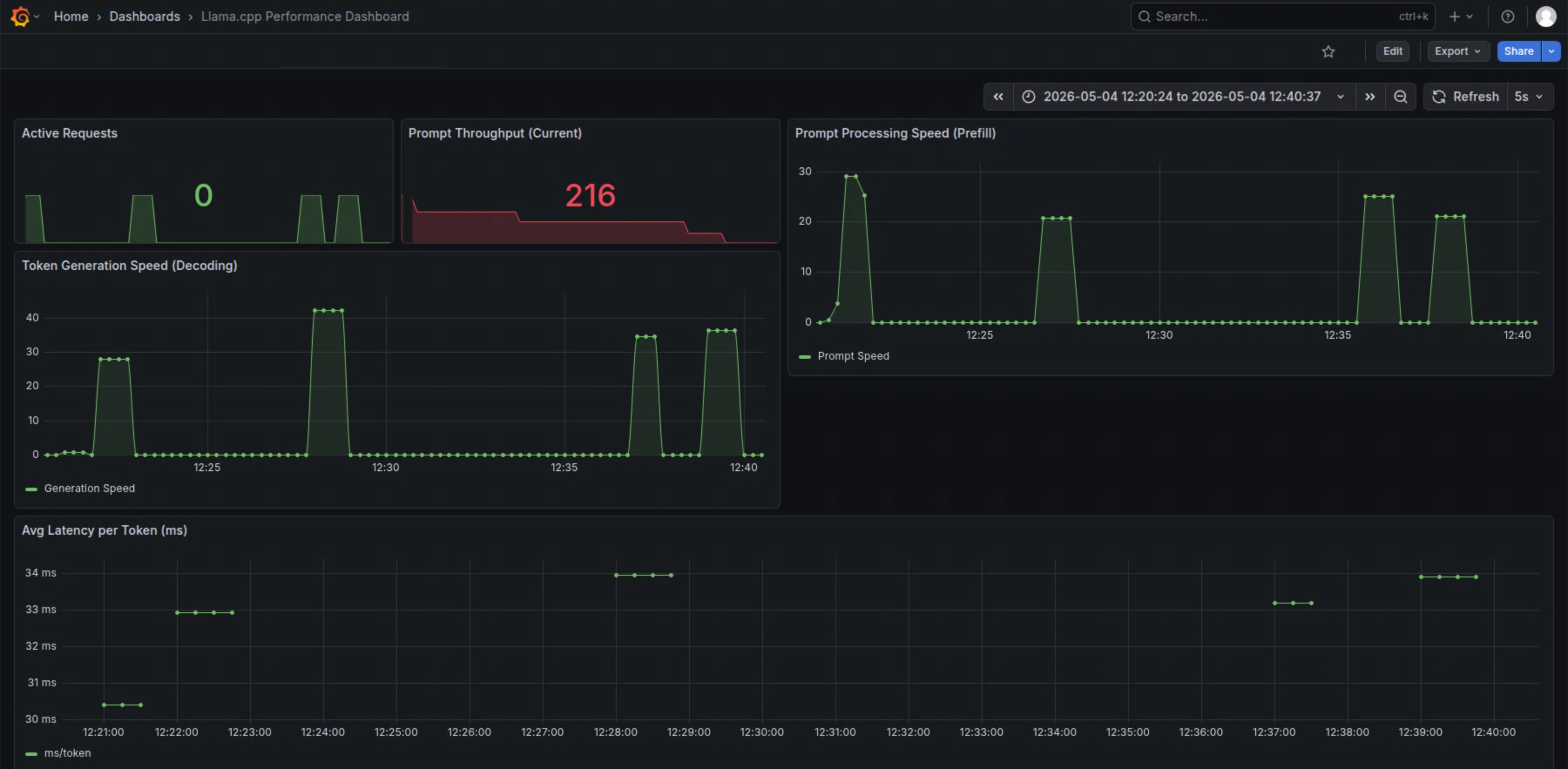
值得注意的是,当我们将 Batch Size 从 1 提升至 1024 时,系统在处理并行请求时的吞吐量表现出了显著的线性增长,这充分证明了 Intel Arc 架构在处理大规模并行张量运算时的吞吐潜力。
6.2 显存利用率与双卡负载均衡 (VRAM & Load Balancing)
这是本次实验最核心的观察点。通过监控 intel_gpu_top 和 nvidia-smi(对应 Intel 版本的监控工具),我们观察到了以下现象:
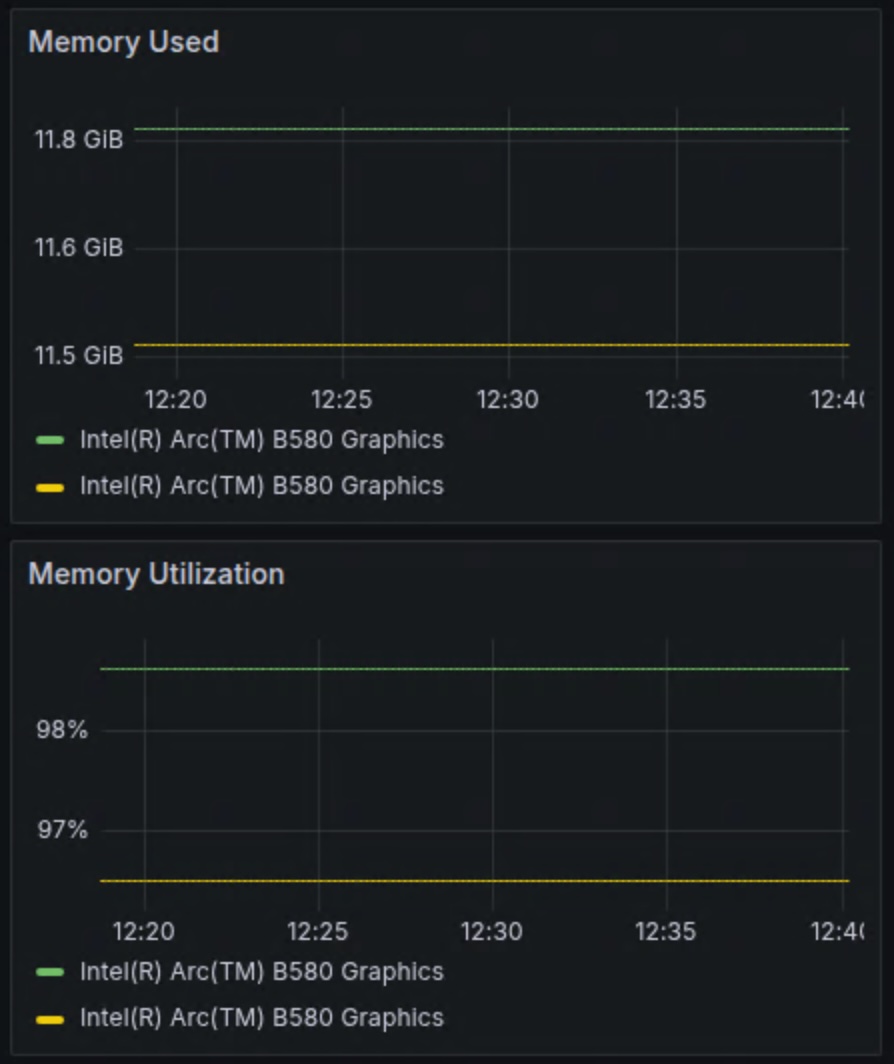
- 显存分布:由于配置了
--tensor-split 0.5,0.5,两张显卡的显存占用呈现出高度的对称性。模型权重被均匀地分布在两块显卡上,没有出现“一卡满载、一卡空闲”的现象。 - 计算负载:两张显卡的执行单元(EU)利用率保持在同步水平。这说明
llama.cpp的张量切分算法在处理双卡异构计算时,能够实现极高的并行效率,有效避免了因单卡计算瓶颈导致的整体等待。 - PCIe 带宽:在双卡频繁交换中间张量时,PCIe 总线并未出现严重的拥塞,验证了 Ultra 9 285K 平台强大的总线带宽支撑能力。
6.3 Agent 认知循环的延迟分析 (The "Agent Tax")
当我们将系统切换到 QwenPaw 的 Agent 模式时,性能指标发生了从“单次推理”到“循环迭代”的转变。我们引入了一个新的观察维度:Agent 响应延迟 (Agentic Latency)。
在 ReAct 模式下,每一次“思考-行动-观察”的循环都会产生额外的开销。这种开销主要来自:
- 工具调用开销:QwenPaw 解析指令并触发本地 Shell/Python 环境的延迟。
- 上下文重构开销:每次观察结果反馈给模型时,需要重新构建包含新信息的 Prompt,这会增加 Prefill(预填充)阶段的计算压力。
工程观察:虽然 Agent 模式的端到端延迟高于单纯的 Chat 模式,但由于 Gemma-4-26B 的推理速度极快,整体交互感依然非常流畅。这种“智力换时间”的权衡(Trade-off)在实际生产场景中是非常划算的。
6.4 系统稳定性与鲁棒性 (Stability & Robustness)
为了测试系统的极限,我们进行了为期 24 小时的压力测试。
- 显存稳定性:在长时间的高负载推理下,显存未出现溢出或碎片化导致的性能退化。
- 容器健壮性:得益于 Docker 的隔离机制与
restart: unless-stopped策略,即便在偶发性的 API 调用异常时,推理服务也能迅速自我恢复。 - 散热表现:双显卡满载运行时,散热风扇的转速曲线平稳,未触发由于过热导致的频率降级(Thermal Throttling)。
7. 总结与展望
通过本次从底层硬件到上层 Agent 框架的全栈构建与实测,我们验证了一个核心命题:高性能、高智力的本地化 AI,并不一定意味着昂贵的硬件垄断。
通过 Intel Arc B580 的显存池化策略、llama.cpp 的高效调度以及 QwenPaw 的 Agent 能力,我们成功在万元级整机上,实现了一个既保障数据主权,又具备实际生产力能力的智能体系统。
然而,这仅仅是本地 AI 演进的一个起点。站在当前的工程实践之上,我们看到了两个极具潜力的演进方向:
7.1 从单体 Agent 向多 Agent 协作集群演进 (Multi-Agent Swarm)
目前的方案展示了一个“全能型” Agent 的能力,但在面对极度复杂的工业级任务时,单一模型往往会面临上下文容量限制与逻辑过载的问题。
未来的演进方向在于“分工与协作”。我们可以利用 QwenPaw 及其背后的编排能力,构建一个多 Agent 协作集群 (Multi-Agent Swarm):
- 专业化分工:不再依靠一个巨大的模型处理所有任务,而是部署多个针对特定领域(如代码审计、文档检索、数据分析)微调过的轻量化模型实例。
- 协作机制:通过一个“主控 Agent”进行任务拆解,分配给不同的“专家 Agent”执行,最后由“审计 Agent”汇总结果。
- 算力弹性:这种模式允许我们根据任务的复杂程度,动态地在硬件集群上调度不同规模的模型,实现效能的最优解。
7.2 从单机工作站向云原生集群扩展 (Scaling via Kubernetes)
目前的 Docker Compose 方案是单机环境下的最优解,但对于追求规模化、高可用性的企业级应用,下一步必须实现“AI 基础设施的云原生化”。
我们可以将 llama.cpp 的推理后端进一步解耦,部署在 Kubernetes (K8s) 集群中:
- 设备插件化 (Device Plugin):通过开发或使用针对 Intel GPU 的 K8s Device Plugin,实现 GPU 资源的标准化调度与分配。
- 自动扩缩容 (Autoscaling):基于推理延迟(Latency)或请求队列长度,自动触发 K8s 的 HPA(水平 Pod 自动扩缩容),实现算力的按需供给。
- 大规模编排:通过 K8s 的调度能力,将成百上千个
llama.cpp推理 Pod 部署在异构的硬件节点上,构建起一个真正意义上的、分布式的本地化 AI 计算网格 (Local AI Computing Grid)。
结语
我们正处于一个技术奇点:算力的获取成本正在下降,而智能的边界正在无限扩张。
对于开发者和企业而言,掌握如何在有限的成本内,通过精妙的工程设计(Engineering Design)构建起稳定、可扩展的 AI 基础设施,将成为未来十年核心的竞争优势。本文所展示的方案,只是通往那个“人人皆有私人智能体”时代的第一个微小足迹。
随着模型量化技术的进一步优化(例如更激进的量化位宽)以及 Intel 硬件生态的持续演进,本地化 Agent 的门槛将进一步降低。对于开发者而言,我们不再需要受困于云端 API 的成本与隐私风险,每个人都可以在自己的桌面上,构建起一个真正属于自己的、全能的数字大脑。